Making Fake Craigslist Posts with Python
March 12, 2019
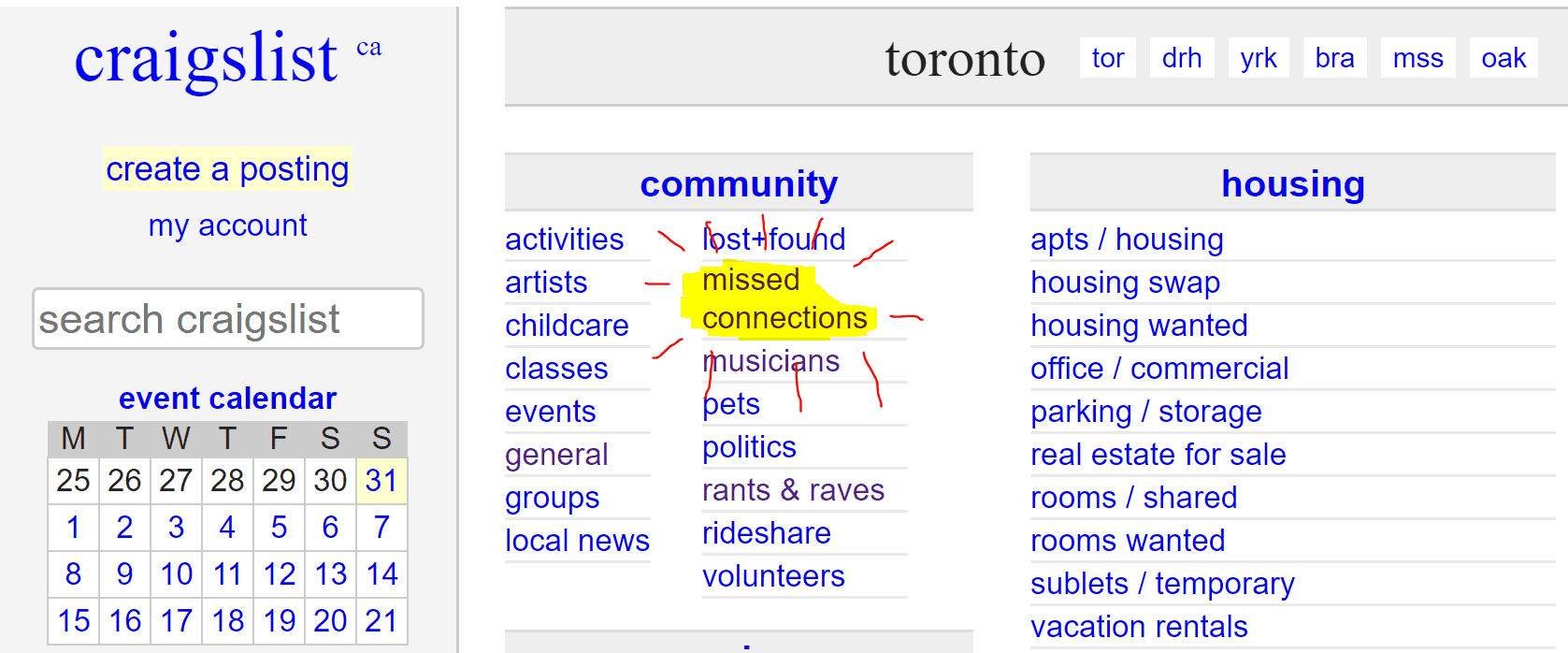
I’ve been looking to do a bit more Python. In a mix of inspiration from an old hackathon project and the Congratulations Podcast - lets generate some fake craigslist posts with Python.
A Markov Chain, simply, is a model of probabilities for transitioning between states. Provided with sequential data, it learns the sequence. In this case, the data is sentences, and the sequence is the progression of one word to another. We’re going to use Markov chains to make a crude natural language model, with the inputs being a feed of Craigslist posts that we’ll scrape with Python.
Heads-up: this makes it… interesting.
How can we use it for language? Well, language isn’t random. When we say a word, grammar and language often dictate for another word to follow. With enough sentences fed into a Markov Chain, it can quickly ‘learn’ general sentence structure, such as:
“I like …”, “I am …”, “I was … then …”, and so on.
As for the gaps - that’s where the material fed to the Markov chain starts filling in like a Mad-Lib. With Craigslist posts, that makes it interesting.
To make the ‘flow’ of generated seem natural, we’re going to make models for each sentence. These posts tend to be 4-5 sentences in length, starting with an introduction and gradually moving through their, uh, story. Funny enough, it actually works.
The results were, uhhh, interesting.
Caution: High probability of some not-G-rated content here:
Below is the function I wrote for model creation. The main model scraping script is in the repo under /scraping. It’s exposed as a CLI using google’s python-fire library
Here’s the libraries used:
import requests
import markovify
import re
from bs4 import BeautifulSoup
from nltk import tokenize
def make_model(self, city_name):
# Figure out how many pages there are
r = requests.get(f'https://{city_name}.craigslist.org/search/mis')
content = BeautifulSoup(r.content,'html.parser')
total_count = int(content.find(class_='totalcount').string)
num_pages = total_count//120+1;
# Initialize Markov chain models using Markovify. Using silly dummy sentences to start.
title_model = markovify.Text("Looking for a guy named John Doe")
location_model = markovify.Text("Main st.")
text_model = markovify.Text("Met John the other day, have you seen him?")
sentence_models = []
# for all the pages of missed connections
for page in range(num_pages):
# Get the post list page, parse it with Beautifulsoup
url = f'https://{city_name}.craigslist.org/search/mis?s={120*page}'
r = requests.get(url)
content = BeautifulSoup(r.content,'html.parser')
# For each post link in the list
for postNum, post in enumerate(content.find_all('a',class_='result-title')):
# Get the actual post
url = post.get('href')
r = requests.get(url)
post_content = BeautifulSoup(r.content,'html.parser')
post_meta = post_content.find(class_='postingtitletext')
# If the post exists (Sometimes the link leads to a post that has been removed)
if post_meta:
# Extract and add Title to model
post_title = post_meta.find(id ='titletextonly').string
post_title = re.sub('[|]|:|-|;|"|(\(|\))|(\[|\])|[\.][\.][\.]|[\']','',post_title)
title = markovify.Text(post_title)
title_model = markovify.combine(models=[title_model, title])
# The following lines are bad code, but BeautifulSoup can't seem to extract the post text easily.
post_text = post_content.find(id='postingbody')
post_text = post_text.div.next_sibling.string
post_text = re.sub('[|]|:|-|;|"|(\(|\))|(\[|\])|[\.][\.][\.]|[\']','',post_text)
post_text = tokenize.sent_tokenize(post_text)
# If the length of the post is longer than sentence models currently made
if len(post_text) > len(sentence_models):
# Add a new sentence model
while len(post_text) > len(sentence_models):
sentence_models.append(markovify.Text('I'))
for i, sentence in enumerate(post_text):
text = markovify.Text(sentence)
sentence_models[i] = markovify.combine(models=[sentence_models[i], text])
print('Processed Post ' + str(postNum+1+120*page) +'/'+ str(total_count-1)+' - ' + post_title)
# Generate Sentences from the Model
print('\nMARKOV GENERATED\n')
print(title_model.make_sentence(tries = 100))
print('\n')
num_sentences = 4 # Random Choice
for i in range(num_sentences):
s = sentence_models[i].make_sentence(tries = 100)
if(s != 'None'):
print(s)

Written by the Andrew Litt who lives and works in Toronto.